
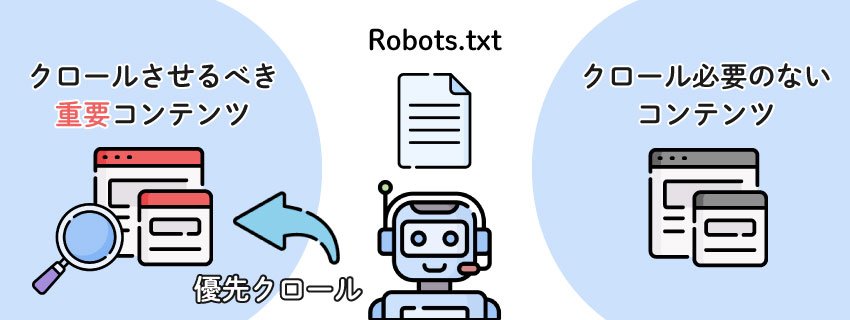
robots.txtの基本構造と書き方は、ウェブサイトのクローラー(検索エンジンのロボット)がどのページやディレクトリにアクセスできるかを制御するためのテキストファイルの記述ルールです。
基本構造
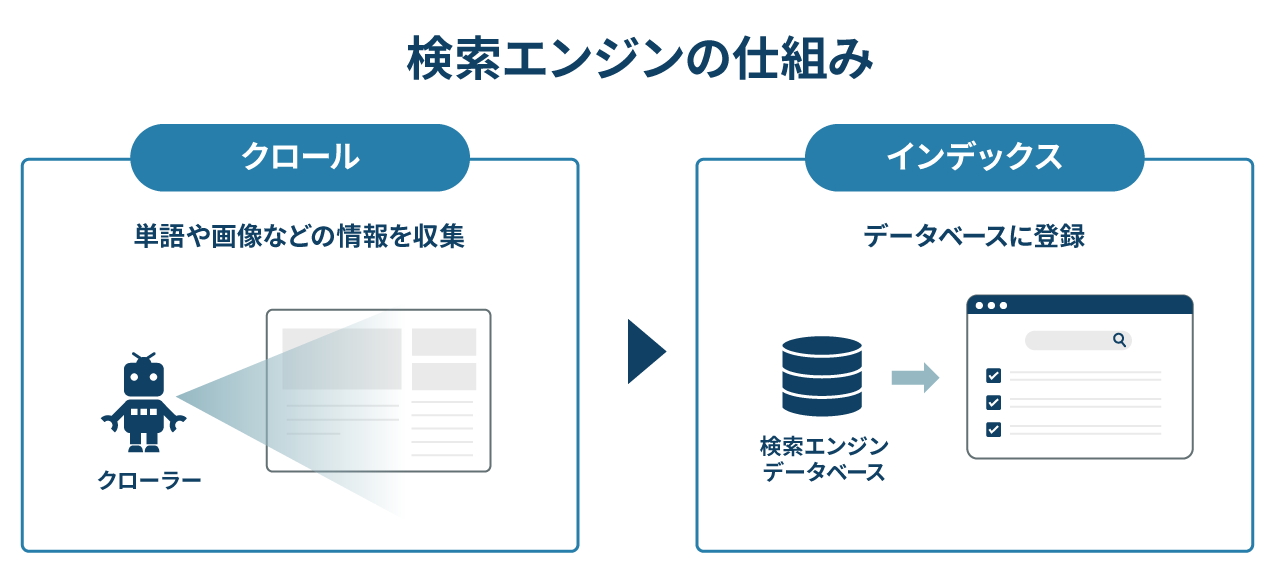
robots.txtはテキストファイルで、主に以下の4つの要素から構成されます。
| 要素 | 説明 | 必須/任意 |
|---|---|---|
| User-agent | 対象とするクローラーの指定(例:Googlebot) | 必須 |
| Disallow | クローラーにアクセスを禁止するパスの指定 | 任意 |
| Allow | Disallowで禁止した中でアクセスを許可するパス | 任意 |
| Sitemap | サイトマップのURLを指定し、クローラーに通知 | 任意 |
書き方の例
User-agent: *
Disallow: /private/
Allow: /private/public-info.html
Sitemap: https://example.com/sitemap.xml
User-agent: *はすべてのクローラーを対象にする指定です。Disallow: /private/は「/private/」以下のページをクロール禁止にします。Allow: /private/public-info.htmlは禁止の中でも特定ページを許可します。Sitemap:はサイトマップの場所をクローラーに知らせます。
ポイント
- User-agent は必ず指定し、対象クローラーを明確にします。
*で全クローラーを指定可能です。 - Disallow はアクセス禁止のパスを指定し、省略するとすべて許可となります。
- Allow はDisallowの例外を指定する際に使います。
- Sitemap はSEOのためにサイトマップのURLを記述しておくと効果的です。
- ファイル名は必ず「robots.txt」とし、ウェブサイトのルートディレクトリに配置します。
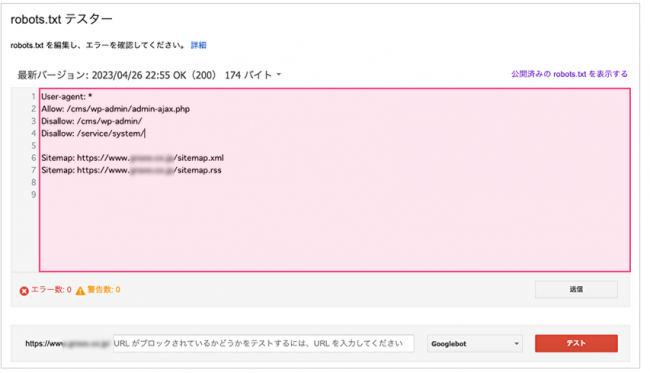
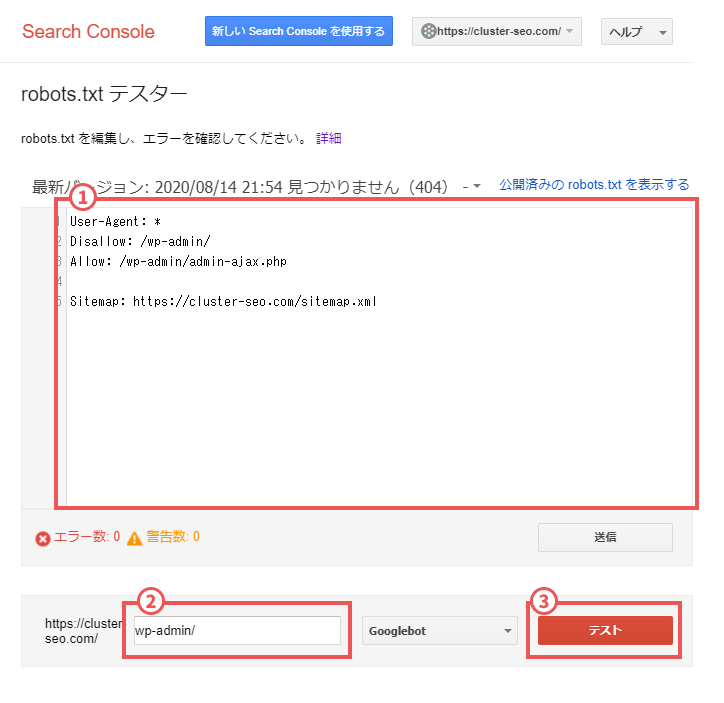
- 作成後はGoogleサーチコンソールの「robots.txtテスターツール」で動作確認を行うことが推奨されます。
注意点
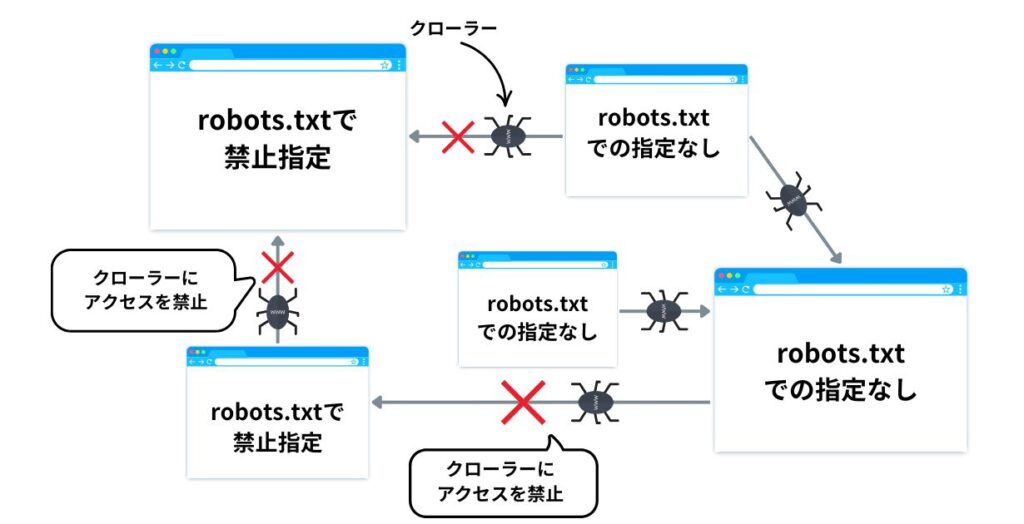
- robots.txtで禁止してもユーザーが直接URLを知っていれば閲覧可能です。
- 一部のクローラーはrobots.txtを無視する場合があります。
- 変更が反映されるまでに1〜2週間かかることがあります。
このように、robots.txtはクローラーのアクセス制御を簡潔に記述するファイルで、SEO対策やサイト運用において重要な役割を持ちます。












JP Ranking は、日本で最高品質のウェブサイトトラフィックサービスを提供しています。ウェブサイトトラフィック、デスクトップトラフィック、モバイルトラフィック、Googleトラフィック、検索トラフィック、eCommerceトラフィック、YouTubeトラフィック、TikTokトラフィックなど、さまざまなトラフィックサービスをクライアントに提供しています。当サイトは100%の顧客満足度を誇り、安心して大量のSEOトラフィックをオンラインで購入できます。月額¥2600で、即座にウェブサイトトラフィックを増加させ、SEOパフォーマンスを改善し、売上を向上させることができます!
トラフィックパッケージの選択にお困りですか?お問い合わせいただければ、スタッフがサポートいたします。
無料相談