
robots.txtに関する主な誤解と落とし穴は以下の通りです。
-
robots.txtはアクセス制限やセキュリティ対策ではない
robots.txtは検索エンジンのクローラーに対して「どのページをクロールしてよいか」を指示するファイルであり、ユーザーの閲覧やアクセスを制限するものではありません。つまり、robots.txtでクロールを禁止しても、そのページがインターネット上で完全に非公開になるわけではなく、URLが知られれば誰でもアクセス可能です。セキュリティ対策としては不十分であり、機密情報は別途認証やアクセス制御を行う必要があります。 -
robots.txtの記述ミスによる誤ったクロール制御
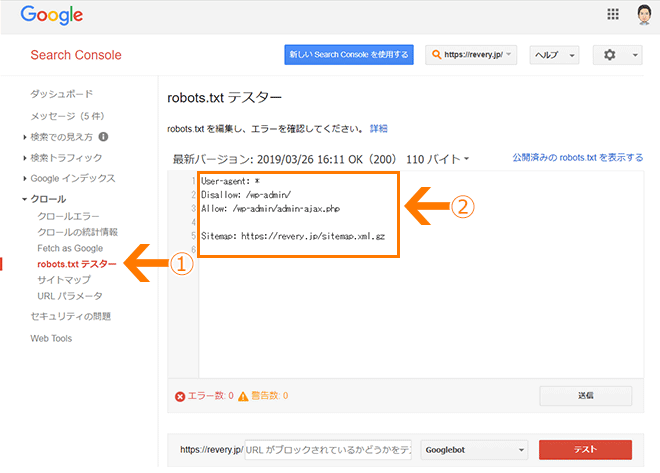
記述方法を誤ると、意図しないページまでクロール禁止になり、検索エンジンのインデックスから重要なページが除外されてしまうことがあります。これにより、検索結果からの流入が大幅に減少するリスクがあります。特に「Disallow: /」のような記述はサイト全体のクロールを禁止してしまうため注意が必要です。 -
robots.txtはあくまで「お願い」であり、すべてのクローラーが従うわけではない
公式の検索エンジンのクローラーはrobots.txtの指示に従いますが、悪意のあるボットや一部のクローラーは無視することがあります。したがって、robots.txtだけでボット対策を完璧に行うことはできません。 -
robots.txtの設置場所とファイル名の重要性
robots.txtは必ずウェブサイトのルートディレクトリに「robots.txt」という名前で設置しなければなりません。誤った場所や名前で設置すると、クローラーが認識できず指示が無効になります。 -
robots.txtとサイトマップの併用
robots.txtはクロール制御のためのファイルですが、サイトマップ(Sitemap.xml)と組み合わせて使うことで、クローラーに効率的にサイト構造を伝えられます。これを知らずにrobots.txtだけで制御しようとすると、クロール効率が落ちることがあります。
これらの誤解や落とし穴を避けるためには、robots.txtの役割を正しく理解し、記述内容を慎重に設計・検証することが重要です。特にSEO対策の一環として利用する場合は、クロール禁止の範囲を明確にし、重要なページが誤って除外されないように注意してください。















JP Ranking は、日本で最高品質のウェブサイトトラフィックサービスを提供しています。ウェブサイトトラフィック、デスクトップトラフィック、モバイルトラフィック、Googleトラフィック、検索トラフィック、eCommerceトラフィック、YouTubeトラフィック、TikTokトラフィックなど、さまざまなトラフィックサービスをクライアントに提供しています。当サイトは100%の顧客満足度を誇り、安心して大量のSEOトラフィックをオンラインで購入できます。月額¥2600で、即座にウェブサイトトラフィックを増加させ、SEOパフォーマンスを改善し、売上を向上させることができます!
トラフィックパッケージの選択にお困りですか?お問い合わせいただければ、スタッフがサポートいたします。
無料相談